AVVF Lab
The Automated Voice Validation Framework: a customizable testbed for measuring the real-world performance of any voice-controlled device, independent of the ASR engine behind it.
Request a QuoteVoice Validation, Independent of the Engine
The AVVF is a Novus Labs-developed test framework that measures the performance of Automated Speech Recognition (ASR) enabled devices, regardless of which engine, cloud service, or platform sits behind them. Whether your device runs on Alexa, Google Assistant, Siri, or a proprietary in-house engine, the AVVF measures what your end user actually experiences.
Our mission with the AVVF is a robust, customizable validation environment for testing, tuning, and improving voice-controlled hardware and software. Each test campaign is tailored to the device under test and the scenarios it has to perform in, from quiet living rooms to noisy retail floors.
- Cloud-service agnostic: works with any ASR engine or backend
- Customizable test scenarios for near-field and far-field applications
- Adaptive learning algorithm automatically determines correct responses
- Custom utterance generation via Speechify, Murf AI, or other TTS tools
- Endpoint and environmental-noise variable coverage

What the AVVF Delivers
Four capabilities that let the AVVF adapt to any voice-controlled device, any ASR backend, and any acoustic environment your product needs to perform in.
- Works with any cloud-based voice recognition service
- Alexa, Google, Siri, or proprietary in-house engines
- No vendor lock-in
- Testbed customized per device
- Models the operational environment the product ships into
- Scales from quiet rooms to noisy retail floors
- Automatically determines correct responses
- End-to-end test scenarios out of the box
- No manual reference-answer input required
- Audio prompts generated from text
- Integrates with Speechify, Murf AI, and other TTS tools
- Drop-in to any test workflow
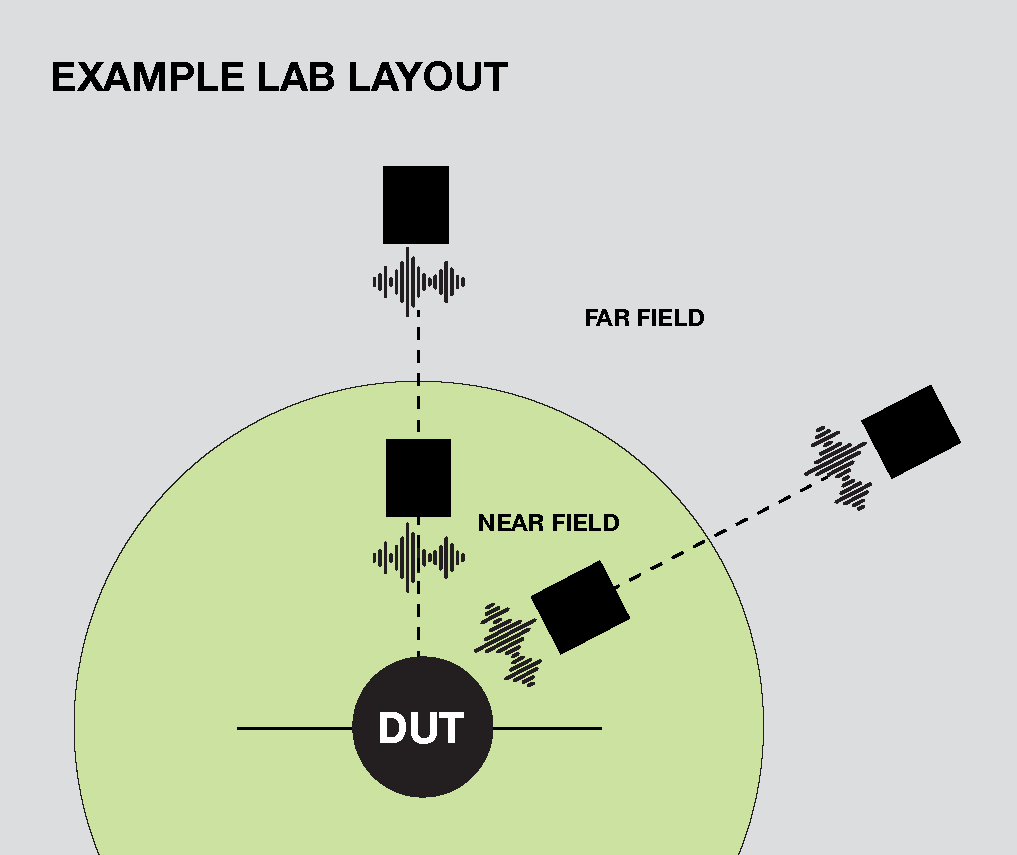
Near Field and Far Field, in One Room
The AVVF supports both predefined test cases and fully customized test scenarios, covering both near-field (close-range, conversational) and far-field (across-the-room) speech recognition use cases.
Speakers positioned around the Device Under Test (DUT) at varying distances simulate the real spatial conditions your product encounters in customer environments, from a phone held up to a user's mouth to a smart speaker fielding voice commands from across the room.
Proven Against Real Devices and Real Noise
To validate the framework itself, Novus implemented a custom endpoint based on the XMOS-3500 platform and interfaced it with several popular voice assistant back-ends. The simulation system was exercised under a wide variety of adverse system tunings and environmental noise conditions to verify it performs reliably across every stage of a product's life cycle.
Endpoint System Variables
Each test campaign exercises adverse system tunings, digital signal processor (DSP) and acoustic echo cancellation (AEC) settings, so the framework's behavior is verified across the full range of device configurations a product may ship with.
Environmental Noise Conditions
Iterations run under silence, pink noise, indoor party noise, rock music, and crowd noise, verifying the framework holds up across every acoustic environment a voice product is likely to encounter in customer hands.
Structured Test Report
Each campaign delivers a structured report covering utterance, device response, score, pass/fail status, and latency metrics for every prompt evaluated.
See It Run
A typical AVVF run: speakers positioned around the Device Under Test deliver a scripted utterance sequence, the framework captures the device's responses, and a CLI overlay logs the result of each prompt. The demo below shows two iterations of the same script (the first under environmental silence, the second with added background noise), illustrating how the framework characterizes voice behavior across acoustic conditions.
Ready to Validate Your Voice Product?
Talk to a Novus engineer about ASR validation, near/far-field testing, custom utterance generation, or noise-condition characterization for your next voice-controlled product.